响应式语音对话应用示例(教程)
本文最后更新于 2024-06-12,文章内容可能已经过时。
原理
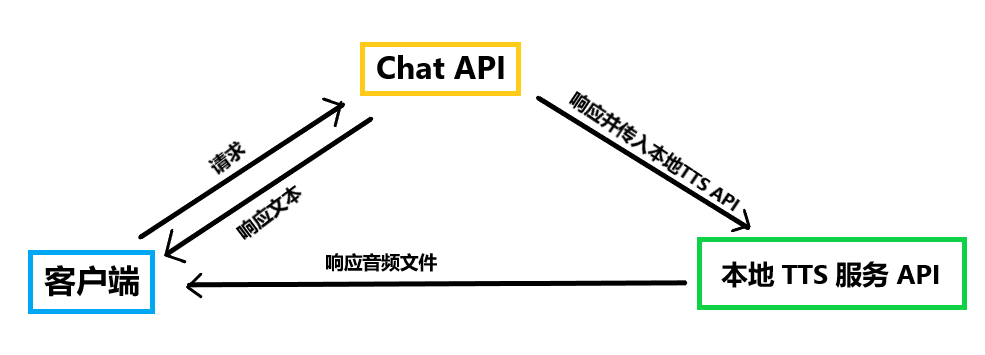
响应式语音对话是基于Chat TTS实现的,通过在本地部署TTS模型进行实时推理,下面是实现原理:
搭建
环境要求:
windows 10/11
python 3.7及以上版本(亲测python3.11版本可用)
Chat TTS本地服务搭建过程:
从github上拉取Chat TTS源代码 (项目地址:cronrpc/ChatTTS-webui: TTS (github.com))
为了方便部署在服务器上使用API远程调用,这里是直接拉取的ChatTTS_Webui的源代码
使用pip安装根目录下requirements.txt文件中依赖项
python -r requirements.txt安装完即可使用一下命令启动Webui
python webui.py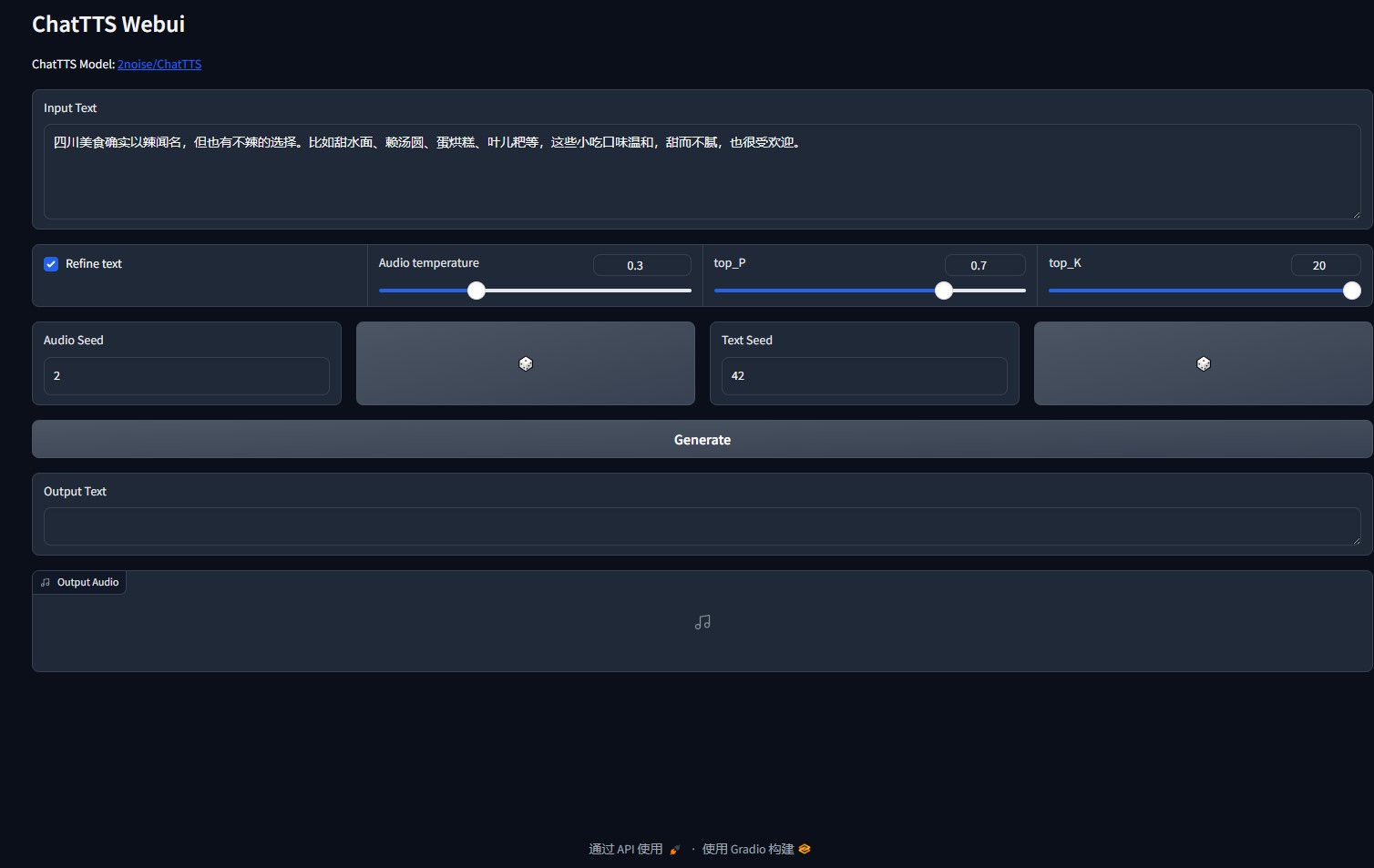
Web ui中提供了多个API接口请求方式,以python为例
from gradio_client import Client
client = Client("http://localhost:8080/")
result = client.predict(
text="你好呀",
temperature=0.3,
top_P=0.7,
top_K=20,
audio_seed_input=2,
text_seed_input=42,
refine_text_flag=True,
api_name="/generate_audio"
)
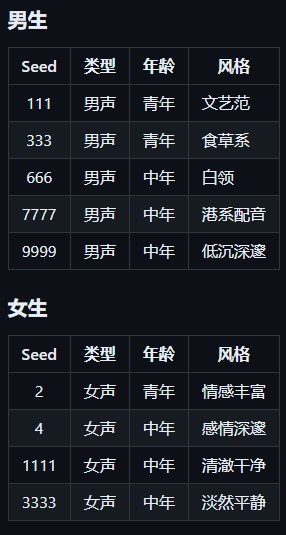
print(result)到这里基本就完成了,下面是关于音色种子的一些示例:
使用
可以通过下列实例代码使用
from gradio_client import Client
import time
import os
import openai
openai.api_key = "API-key"
uuu = input("user:")
messages = [
{"role": "system", "content": '你是一个助手'},
{"role": "user", "content": uuu}
]
response = openai.ChatCompletion.create(
model="gpt-4o", # 选择使用的模型
messages=messages, # 设定对话历史消息
temperature=0.7, # 控制生成文本的创造性(可选)
max_tokens=50 # 生成的最大标记数(可选)
)
generated_text = response['choices'][0]['message']['content']
# 输出 OpenAI 的回复
print("API 响应:", generated_text.strip())
client = Client("http://localhost:8080/")
result = client.predict(
text=generated_text.strip(),
temperature=0.35709,
top_P=0.7,
top_K=20,
audio_seed_input=41438986,
text_seed_input=59862103,
refine_text_flag=True,
api_name="/generate_audio"
)
print(result)
api_response = (result)
path = api_response[0] # 获取路径部分
print(path)
import pygame
pygame.mixer.init()
pygame.time.delay(2000)
pygame.mixer.music.load(path)
pygame.mixer.music.set_volume(0.5)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
time.sleep(1) # 等待1秒钟
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Aya
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果