响应式语音对话应用示例(教程)
本文最后更新于 2024-06-12,文章内容可能已经过时。
原理
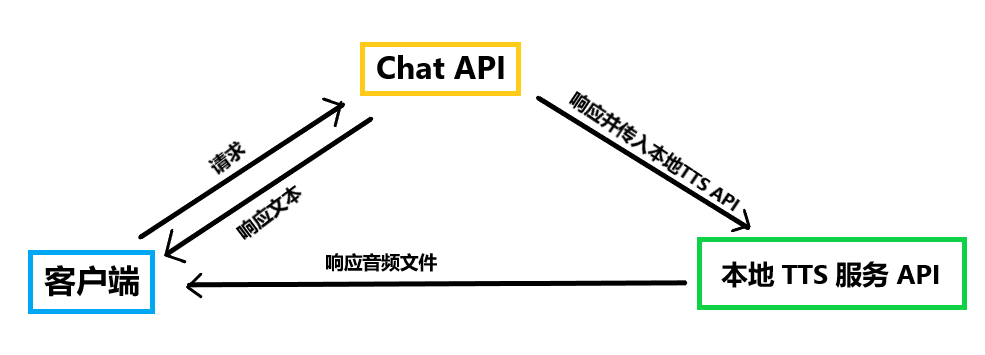
响应式语音对话是基于Chat TTS实现的,通过在本地部署TTS模型进行实时推理,下面是实现原理:
搭建
环境要求:
windows 10/11
python 3.7及以上版本(亲测python3.11版本可用)
Chat TTS本地服务搭建过程:
从github上拉取Chat TTS源代码 (项目地址:cronrpc/ChatTTS-webui: TTS (github.com))
为了方便部署在服务器上使用API远程调用,这里是直接拉取的ChatTTS_Webui的源代码
使用pip安装根目录下requirements.txt文件中依赖项
安装完即可使用一下命令启动Webui
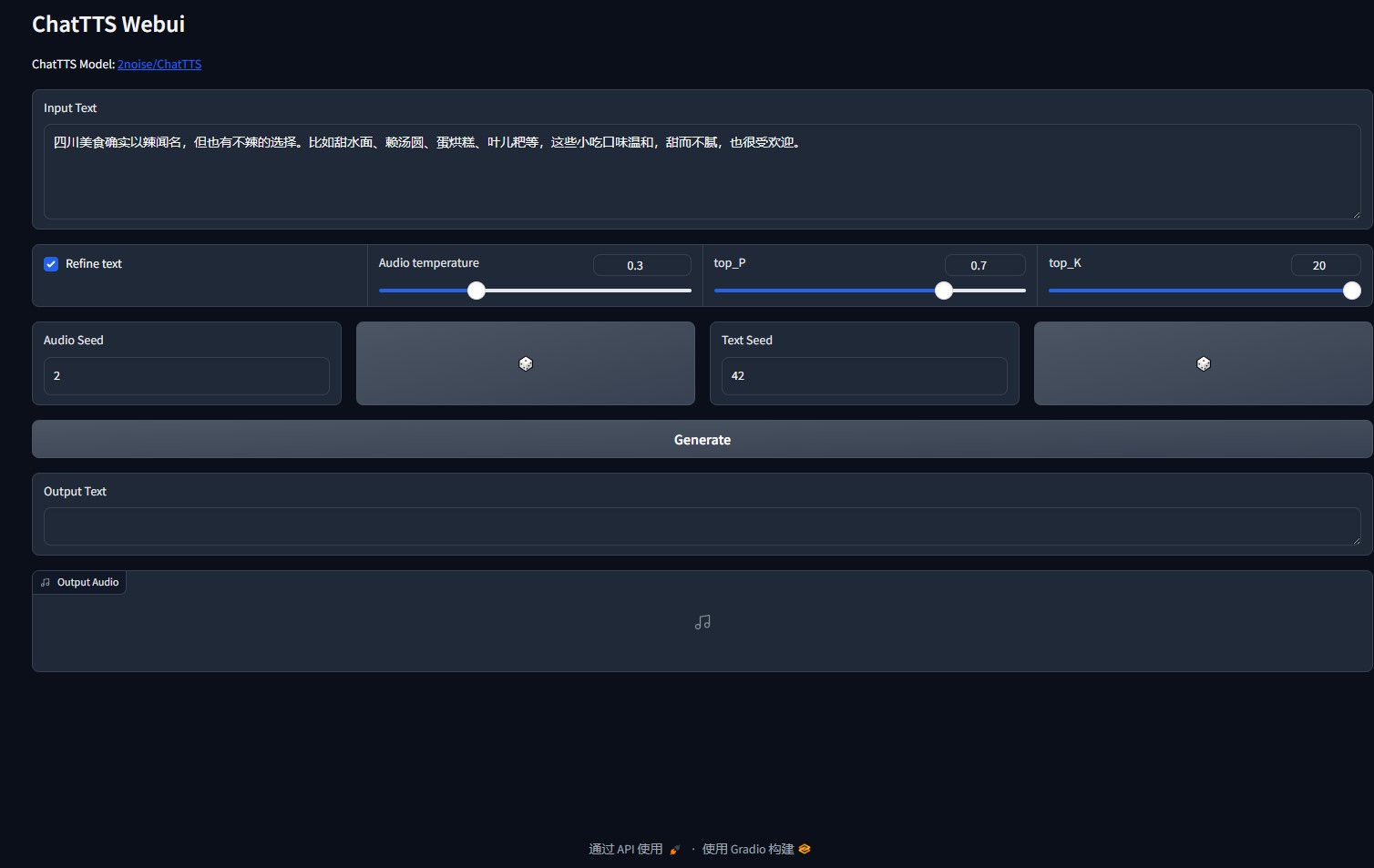
Web ui中提供了多个API接口请求方式,以python为例
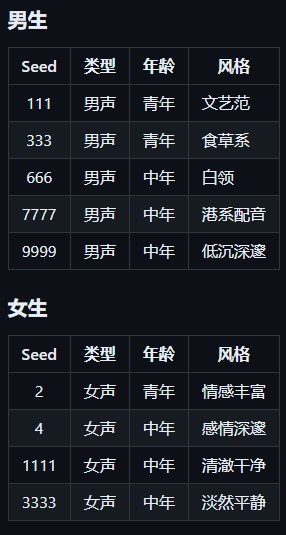
到这里基本就完成了,下面是关于音色种子的一些示例:
使用
可以通过下列实例代码使用

使用手机访问这篇文章
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 Aya
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果